计算机网络体系结构分层:
| OSI 七层模型 | TCP/IP 概念层模型 | 功能 | TCP/IP 协议族 |
|---|---|---|---|
| 应用层 | 应用层 | 文件传输,电子邮件,文件服务,虚拟终端 | TFTP, HTTP, SNMP, FTP, SMTP, DNS, Telnet |
| 表示层 | 数据格式化,代码转换,数据加密 | 没有协议 | |
| 会话层 | 解除或建立与别的接点的联系 | 没有协议 | |
| 传输层 | 传输层 | 提供端对端的接口 | TCP, UDP |
| 网络层 | 网络层 | 为数据包选择路由 | IP, ICMP, RIP, OSPF, BGP, IGMP |
| 数据链路层 | 链路层 | 传输有地址的帧以及错误检测功能 | SLIP, CSLIP, PPP, ARP, RARP, MTU |
| 物理层 | 以二进制数据形式在物理媒体上传输数据 | ISO2110, IEEE802, IEEE802.2 |
# UDP
# 面向报文
UDP 是一个面向报文(报文可以理解为一段段的数据)的协议。意思就是 UDP 只是报文的搬运工,不会对报文进行任何拆分和拼接操作。
具体来说:
- 在发送端,应用层将数据传递给传输层的 UDP 协议,UDP 只会给数据增加一个 UDP 头标识下是 UDP 协议,然后就传递给网络层了
- 在接收端,网络层将数据传递给传输层,UDP 只去除 IP 报文头就传递给应用层,不会任何拼接操作
# 不可靠性
UDP 是无连接的,也就是说通信不需要建立和断开连接。 UDP 也是不可靠的。协议收到什么数据就传递什么数据,并且也不会备份数据,对方能不能收到是不关心的 UDP 没有拥塞控制,一直会以恒定的速度发送数据。即使网络条件不好,也不会对发送速率进行调整。这样实现的弊端就是在网络条件不好的情况下可能会导致丢包,但是优点也很明显,在某些实时性要求高的场景(比如电话会议)就需要使用 UDP 而不是 TCP。
# 高效
因为 UDP 没有 TCP 那么复杂,需要保证数据不丢失且有序到达。所以 UDP 的头部开销小,只有八字节,相比 TCP 的至少二十字节要少得多,在传输数据报文时是很高效的。
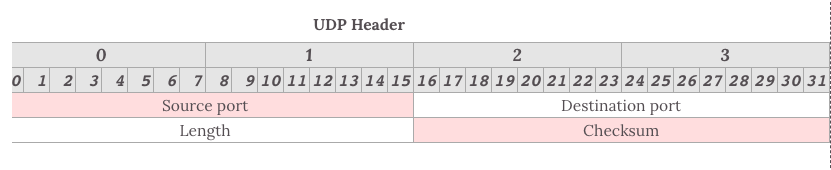
头部包含了以下几个数据:
- 两个十六位的端口号,分别为源端口(可选字段)和目标端口
- 整个数据报文的长度
- 整个数据报文的检验和(IPv4 可选 字段),该字段用于发现头部信息和数据中的错误
# 传输方式
UDP 不止支持一对一的传输方式,同样支持一对多,多对多,多对一的方式,也就是说 UDP 提供了单播,多播,广播的功能。
# TCP
TCP 头部比 UDP 头部复杂的多:
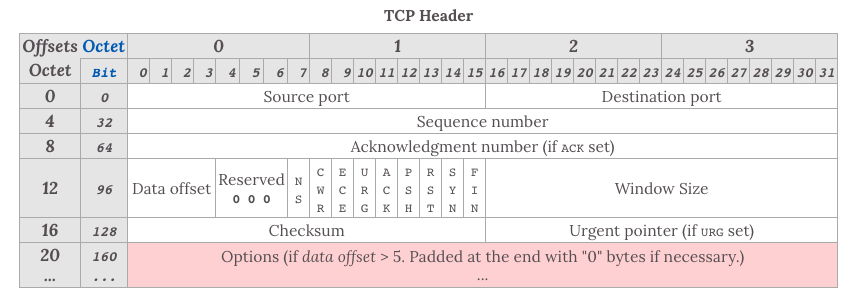
对于 TCP 头部来说,以下几个字段是很重要的
- Sequence number,这个序号保证了 TCP 传输的报文都是有序的,对端可以通过序号顺序的拼接报文
- Acknowledgement Number,这个序号表示数据接收端期望接收的下一个字节的编号是多少,同时也表示上一个序号的数据已经收到
- Window Size,窗口大小,表示还能接收多少字节的数据,用于流量控制
- 标识符
URG=1: 该字段为一表示本数据报的数据部分包含紧急信息,是一个高优先级数据报文,此时紧急指针有效。紧急数据一定位于当前数据包数据部分的最前面,紧急指针标明了紧急数据的尾部。ACK=1: 该字段为一表示确认号字段有效。此外,TCP 还规定在连接建立后传送的所有报文段都必须把 ACK 置为一。PSH=1: 该字段为一表示接收端应该立即将数据 push 给应用层,而不是等到缓冲区满后再提交。RST=1: 该字段为一表示当前 TCP 连接出现严重问题,可能需要重新建立 TCP 连接,也可以用于拒绝非法的报文段和拒绝连接请求。SYN=1: 当 SYN=1,ACK=0 时,表示当前报文段是一个连接请求报文。当 SYN=1,ACK=1 时,表示当前报文段是一个同意建立连接的应答报文。FIN=1: 该字段为一表示此报文段是一个释放连接的请求报文。
# 状态机
HTTP 是无连接的,所以作为下层的 TCP 协议也是无连接的,虽然看似 TCP 将两端连接了起来,但是其实只是两端共同维护了一个状态:

TCP 的状态机是很复杂的,并且与建立断开连接时的握手息息相关,接下来就来详细描述下两种握手。
RTT: Round-Trip Time, 往返时延。在计算机⽹络中它是⼀个重要的性能指标,表⽰从发送端发送数据开始,到发送端收到来⾃接收端的确认(接收端收到数据后便立即发送确认),总共经历的时延。
在 TCP 协议中,主动发起请求的一端为客户端,被动连接的一端称为服务端。不管是客户端还是服务端,TCP 连接建立完后都能发送和接收数据,所以 TCP 也是一个全双工的协议。
# 三次握手
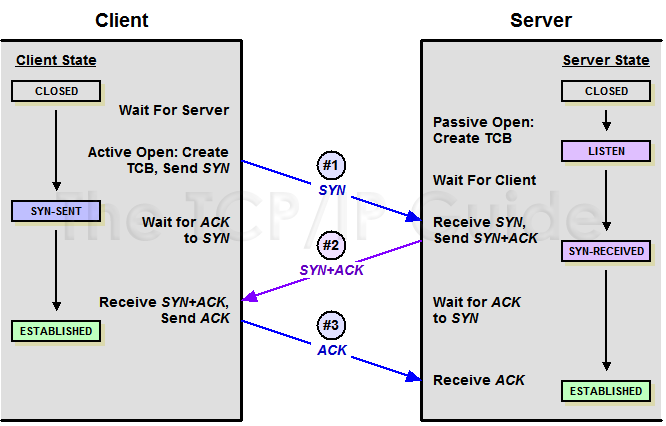
起初,两端都为 CLOSED 状态。在通信开始前,双方都会创建 TCB。 服务器创建完 TCB 后遍进入 LISTEN 状态,此时开始等待客户端发送数据。
第一次握手:
客户端向服务端发送连接请求报文段。该报文段中包含自身的数据通讯初始序号。请求发送后,客户端便进入 SYN-SENT 状态,x 表示客户端的数据通信初始序号。
第二次握手:
服务端收到连接请求报文段后,如果同意连接,则会发送一个应答,该应答中也会包含自身的数据通讯初始序号,发送完成后便进入 SYN-RECEIVED 状态。
第三次握手:
当客户端收到连接同意的应答后,还要向服务端发送一个确认报文。客户端发完这个报文段后便进入 ESTABLISHED 状态,服务端收到这个应答后也进入 ESTABLISHED 状态,此时连接建立成功。
PS:第三次握手可以包含数据,通过 TCP 快速打开(TFO)技术。其实只要涉及到握手的协议,都可以使用类似 TFO 的方式,客户端和服务端存储相同 cookie,下次握手时发出 cookie 达到减少 RTT 的目的。
你是否有疑惑明明两次握手就可以建立起连接,为什么还需要第三次应答?
因为这是为了防止失效的连接请求报文段被服务端接收,从而产生错误。
可以想象如下场景。客户端发送了一个连接请求 A,但是因为网络原因造成了超时,这时 TCP 会启动超时重传的机制再次发送一个连接请求 B。此时请求顺利到达服务端,服务端应答完就建立了请求。如果连接请求 A 在两端关闭后终于抵达了服务端,那么这时服务端会认为客户端又需要建立 TCP 连接,从而应答了该请求并进入 ESTABLISHED 状态。此时客户端其实是 CLOSED 状态,那么就会导致服务端一直等待,造成资源的浪费。
PS:在建立连接中,任意一端掉线,TCP 都会重发 SYN 包,一般会重试五次,在建立连接中可能会遇到 SYN FLOOD 攻击。遇到这种情况你可以选择调低重试次数或者干脆在不能处理的情况下拒绝请求。
# 四次挥手
TCP 是全双工的,在断开连接时两端都需要发送 FIN 和 ACK。
第一次挥手:
若客户端 A 认为数据发送完成,则它需要向服务端 B 发送连接释放请求。
第二次挥手:
B 收到连接释放请求后,会告诉应用层要释放 TCP 链接。然后会发送 ACK 包,并进入 CLOSE_WAIT 状态,表示 A 到 B 的连接已经释放,不接收 A 发的数据了。但是因为 TCP 连接时双向的,所以 B 仍旧可以发送数据给 A。
第三次挥手:
B 如果此时还有没发完的数据会继续发送,完毕后会向 A 发送连接释放请求,然后 B 便进入 LAST-ACK 状态。
PS:通过延迟确认的技术(通常有时间限制,否则对方会误认为需要重传),可以将第二次和第三次挥手合并,延迟 ACK 包的发送。
第四次挥手:
A 收到释放请求后,向 B 发送确认应答,此时 A 进入 TIME-WAIT 状态。该状态会持续 2MSL(最大段生存期,指报文段在网络中生存的时间,超时会被抛弃) 时间,若该时间段内没有 B 的重发请求的话,就进入 CLOSED 状态。当 B 收到确认应答后,也便进入 CLOSED 状态。
为什么 A 要进入 TIME-WAIT 状态,等待 2MSL 时间后才进入 CLOSED 状态?
为了保证 B 能收到 A 的确认应答。若 A 发完确认应答后直接进入 CLOSED 状态,如果确认应答因为网络问题一直没有到达,那么会造成 B 不能正常关闭。
# ARQ 协议
ARQ 协议也就是超时重传机制。通过确认和超时机制保证了数据的正确送达,ARQ 协议包含停止等待 ARQ 和连续 ARQ
# 停止等待 ARQ
正常传输过程:
只要 A 向 B 发送一段报文,都要停止发送并启动一个定时器,等待对端回应,在定时器时间内接收到对端应答就取消定时器并发送下一段报文。
报文丢失或出错:
在报文传输的过程中可能会出现丢包。这时候超过定时器设定的时间就会再次发送丢包的数据直到对端响应,所以需要每次都备份发送的数据。
即使报文正常的传输到对端,也可能出现在传输过程中报文出错的问题。这时候对端会抛弃该报文并等待 A 端重传。
PS:一般定时器设定的时间都会大于一个 RTT 的平均时间。
ACK 超时或丢失:
对端传输的应答也可能出现丢失或超时的情况。那么超过定时器时间 A 端照样会重传报文。这时候 B 端收到相同序号的报文会丢弃该报文并重传应答,直到 A 端发送下一个序号的报文。
在超时的情况下也可能出现应答很迟到达,这时 A 端会判断该序号是否已经接收过,如果接收过只需要丢弃应答即可。
这个协议的缺点就是传输效率低,在良好的网络环境下每次发送报文都得等待对端的 ACK。
# 连续 ARQ
在连续 ARQ 中,发送端拥有一个发送窗口,可以在没有收到应答的情况下持续发送窗口内的数据,这样相比停止等待 ARQ 协议来说减少了等待时间,提高了效率。
累计确认:
连续 ARQ 中,接收端会持续不断收到报文。如果和停止等待 ARQ 中接收一个报文就发送一个应答一样,就太浪费资源了。通过累计确认,可以在收到多个报文以后统一回复一个应答报文。报文中的 ACK 可以用来告诉发送端这个序号之前的数据已经全部接收到了,下次请发送这个序号 + 1的数据。
但是累计确认也有一个弊端。在连续接收报文时,可能会遇到接收到序号 5 的报文后,并未接到序号 6 的报文,然而序号 7 以后的报文已经接收。遇到这种情况时,ACK 只能回复 6,这样会造成发送端重复发送数据,这种情况下可以通过 Sack 来解决,这个会在下文说到。
# 滑动窗口
在上面小节中讲到了发送窗口。在 TCP 中,两端都维护着窗口:分别为发送端窗口和接收端窗口。
发送端窗口包含已发送但未收到应答的数据和可以发送但是未发送的数据。
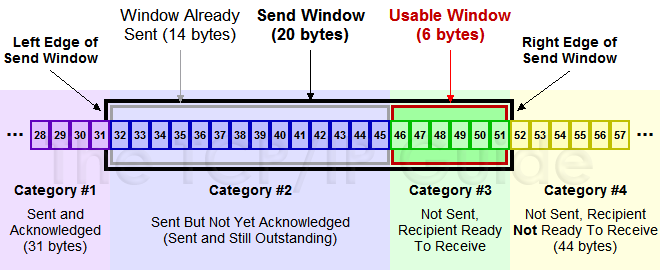
发送端窗口是由接收窗口剩余大小决定的。接收方会把当前接收窗口的剩余大小写入应答报文,发送端收到应答后根据该值和当前网络拥塞情况设置发送窗口的大小,所以发送窗口的大小是不断变化的。
当发送端接收到应答报文后,会随之将窗口进行滑动:
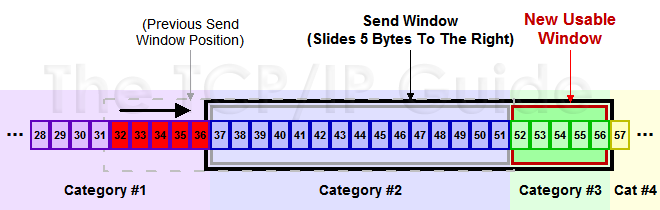
滑动窗口实现了流量控制。接收方通过报文告知发送方还可以发送多少数据,从而保证接收方能够来得及接收数据。
# Zero 窗口
在发送报文的过程中,可能会遇到对端出现零窗口的情况。在该情况下,发送端会停止发送数据,并启动 persistent timer 。该定时器会定时发送请求给对端,让对端告知窗口大小。在重试次数超过一定次数后,可能会中断 TCP 链接。
# 拥塞处理
拥塞处理和流量控制不同,后者是作用于接收方,保证接收方来得及接受数据。而前者是作用于网络,防止过多的数据拥塞网络,避免出现网络负载过大的情况。
拥塞处理包括了四个算法,分别为:慢开始,拥塞避免,快速重传,快速恢复。
# 慢开始算法
慢开始算法,顾名思义,就是在传输开始时将发送窗口慢慢指数级扩大,从而避免一开始就传输大量数据导致网络拥塞。
慢开始算法步骤具体如下:
- 连接初始设置拥塞窗口(Congestion Window) 为 1 MSS(一个分段的最大数据量)
- 每过一个 RTT 就将窗口大小乘二
- 指数级增长肯定不能没有限制的,所以有一个阈值限制,当窗口大小大于阈值时就会启动拥塞避免算法。
# 拥塞避免算法
拥塞避免算法相比简单点,每过一个 RTT 窗口大小只加一,这样能够避免指数级增长导致网络拥塞,慢慢将大小调整到最佳值。
在传输过程中可能定时器超时的情况,这时候 TCP 会认为网络拥塞了,会马上进行以下步骤:
- 将阈值设为当前拥塞窗口的一半
- 将拥塞窗口设为 1 MSS
- 启动拥塞避免算法
# 快速重传
快速重传一般和快恢复一起出现。一旦接收端收到的报文出现失序的情况,接收端只会回复最后一个顺序正确的报文序号(没有 Sack 的情况下)。如果收到三个重复的 ACK,无需等待定时器超时再重发而是启动快速重传。具体算法分为两种:
TCP Taho 实现如下:
- 将阈值设为当前拥塞窗口的一半
- 将拥塞窗口设为 1 MSS
- 重新开始慢开始算法
TCP Reno 实现如下:
- 拥塞窗口减半
- 将阈值设为当前拥塞窗口
- 进入快恢复阶段(重发对端需要的包,一旦收到一个新的 ACK 答复就退出该阶段)
- 使用拥塞避免算法
# TCP New Ren 改进后的快恢复
TCP New Reno 算法改进了之前 TCP Reno 算法的缺陷。在之前,快恢复中只要收到一个新的 ACK 包,就会退出快恢复。
在 TCP New Reno 中,TCP 发送方先记下三个重复 ACK 的分段的最大序号。
假如我有一个分段数据是 1 ~ 10 这十个序号的报文,其中丢失了序号为 3 和 7 的报文,那么该分段的最大序号就是 10。发送端只会收到 ACK 序号为 3 的应答。这时候重发序号为 3 的报文,接收方顺利接收并会发送 ACK 序号为 7 的应答。这时候 TCP 知道对端是有多个包未收到,会继续发送序号为 7 的报文,接收方顺利接收并会发送 ACK 序号为 11 的应答,这时发送端认为这个分段接收端已经顺利接收,接下来会退出快恢复阶段。
# DNS
DNS 的作用就是通过域名查询到具体的 IP。
因为 IP 存在数字和英文的组合(IPv6),很不利于人类记忆,所以就出现了域名。你可以把域名看成是某个 IP 的别名,DNS 就是去查询这个别名的真正名称是什么。
在 TCP 握手之前就已经进行了 DNS 查询,这个查询是操作系统自己做的。当你在浏览器中想访问 www.google.com 时,会进行以下操作:
- 操作系统会首先在本地缓存中查询
- 没有的话会去系统配置的 DNS 服务器中查询
- 如果这时候还没得话,会直接去 DNS 根服务器查询,这一步查询会找出负责
com这个一级域名的服务器 - 然后去该服务器查询 google 这个二级域名
- 接下来三级域名的查询其实是我们配置的,你可以给 www 这个域名配置一个 IP,然后还可以给别的三级域名配置一个 IP
以上介绍的是 DNS 迭代查询,还有种是递归查询,区别就是前者是由客户端去做请求,后者是由系统配置的 DNS 服务器做请求,得到结果后将数据返回给客户端。
PS:DNS 是基于 UDP 做的查询。
# HTTP
HTTP, HyperText Transfer Protocol,超文本传输协议超文本传输协议。「是一个在计算机世界里专门在两点之间传输文字、图片、音频、视频等超文本数据的约定和规范」。
# 特点
- 灵活可扩展:主要体现在两个方面。一个是语义上的自由,只规定了基本格式,比如空格分隔单词,换行分隔字段,其他的各个部分都没有严格的语法限制。另一个是传输形式的多样性,不仅仅可以传输文本,还能传输图片、视频等任意数据,非常方便。
- 请求-应答:也就是一发一收、有来有回,当然这个请求方和应答方不单单指客户端和服务器之间,如果某台服务器作为代理来连接后端的服务端,那么这台服务器也会扮演请求方的角色。
- 可靠传输:HTTP 是基于 TCP/IP,因此把这一特性继承了下来。
- 无状态:这里的状态是指通信过程的上下文信息,而每次 http 请求都是独立、无关的,默认不需要保留状态信息。
# 缺点
- 无状态:是特点同时也是缺点,区分场景看待,比如在需要长连接的场景中,需要保存大量的上下文信息,以免传输大量重复的信息,那么这时候无状态就是 http 的缺点了。
- 明文传输:即协议里的报文(主要指的是头部)不使用二进制数据,而是文本形式。这让HTTP的报文信息暴露给了外界,给攻击者带来了便利。
- 队头阻塞:当 http 开启长连接时,共用一个 TCP 连接,当某个请求时间过长时,其他的请求只能处于阻塞状态,这就是队头阻塞问题。
# 请求方法
HTTP/1.1 规定了以下请求方法(注意,都是大写):
GET: 通常用来获取资源HEAD: 获取资源的元信息POST: 提交数据,即上传数据PUT: 修改数据DELETE: 删除资源(几乎用不到)CONNECT: 建立连接隧道,用于代理服务器OPTIONS: 列出可对资源实行的请求方法,用来跨域请求TRACE: 追踪请求-响应的传输路径
GET 和 POST 有什么区别?
首先最直观的是语义上的区别。
而后又有这样一些具体的差别:
- 从缓存的角度,GET 请求会被浏览器主动缓存下来,留下历史记录,而 POST 默认不会。
- 从编码的角度,GET 只能进行 URL 编码,只能接收 ASCII 字符,而 POST 没有限制。
- 从参数的角度,GET 一般放在 URL 中,因此不安全,POST 放在请求体中,更适合传输敏感信息。
- 从幂等性的角度,GET 是幂等的,而 POST 不是。(幂等表示执行相同的操作,结果也是相同的)
- 从 TCP 的角度,GET 请求会把请求报文一次性发出去,而 POST 会分为两个 TCP 数据包,首先发 header 部分,如果服务器响应 100(continue), 然后发 body 部分。(火狐浏览器除外,它的 POST 请求只发一个 TCP 包)
# 报文结构
用于 HTTP 协议交互的信息被称为 HTTP 报文。客户端的 HTTP 报文叫请求报文,服务端的 HTTP 报文叫响应报文。
HTTP 报文结构可以表示为 起始行 + 头部 + 空行 + 实体,请求报文和响应报文有一定区别,我们分开介绍。
# 请求报文
┌─> ┌────────────┬────┬───────┬────┬───────────┬──────┐
Request line ─┤ │ Method │ SP │ URI │ SP │ Version │ CRLF │
├─> ├────────────┼────┼───────┴────┴───────────┼──────┤
│ │ Field Name │ : │ Field Value │ CRLF │
│ ├────────────┴────┴────────────────────────┴──────┤
Headers ─┤ │ ... │
│ ├────────────┬────┬────────────────────────┬──────┤
│ │ Field Name │ : │ Field Value │ CRLF │
├─> ├────────────┴────┴────────────────────────┴──────┤
Blank line ─┤ │ CRLF │
├─> ├─────────────────────────────────────────────────┤
Request body ─┤ │ ... │
└─> └─────────────────────────────────────────────────┘
- 请求行:请求方法(Method) + 空格 + 统一资源标识符(URI) + 空格 + HTTP 版本 + CRLF
- 请求头:字段名 + 冒号 + 值 + CRLF
- 空行: 回车符(CR)+ 换行符(LF)
- 请求体: 由用户自定义添加,如 post 的 body 等
# 响应报文
┌─> ┌────────────┬────┬─────────────┬────┬────────┬──────┐
Status line ─┤ │ Version │ SP │ Status Code │ SP │ Reason │ CRLF │
├─> ├────────────┼────┼─────────────┴────┴────────┼──────┤
│ │ Field Name │ : │ Field Value │ CRLF │
│ ├────────────┴────┴───────────────────────────┴──────┤
Headers ─┤ │ ... │
│ ├────────────┬────┬───────────────────────────┬──────┤
│ │ Field Name │ : │ Field Value │ CRLF │
├─> ├────────────┴────┴───────────────────────────┴──────┤
Blank line ─┤ │ CRLF │
├─> ├────────────────────────────────────────────────────┤
Response body ─┤ │ ... │
└─> └────────────────────────────────────────────────────┘
- 状态行:HTTP 版本 + 空格 + 状态码 + 空格 + 状态码描述 + CRLF
- 响应头:字段名 + 冒号 + 值 + CRLF
- 空行: 回车符(CR)+ 换行符(LF)
- 响应体: 由用户自定义添加,如 post 的 body 等
常见的响应状态码:
- 1xx: 表示目前是协议处理的中间状态,还需要后续操作
- 2xx: 表示成功状态
- 3xx: 重定向状态,资源位置发生变动,需要重新请求
- 4xx: 请求报文有误
- 5xx: 服务器端发生错误
详细的说明可参考 HTTP 状态码速查
# HTTP 首部
| 通用字段 | 作用 |
|---|---|
| Cache-Control | 控制缓存的行为 |
| Connection | 浏览器想要优先使用的连接类型,比如 keep-alive |
| Date | 创建报文时间 |
| Pragma | 报文指令 |
| Via | 代理服务器相关信息 |
| Transfer-Encoding | 传输编码方式 |
| Upgrade | 要求客户端升级协议 |
| Warning | 在内容中可能存在错误 |
| 请求字段 | 作用 |
|---|---|
| Accept | 能正确接收的媒体类型 |
| Accept-Charset | 能正确接收的字符集 |
| Accept-Encoding | 能正确接收的编码格式列表 |
| Accept-Language | 能正确接收的语言列表 |
| Expect | 期待服务端的指定行为 |
| From | 请求方邮箱地址 |
| Host | 服务器的域名 |
| If-Match | 两端资源标记比较 |
| If-Modified-Since | 本地资源未修改返回 304(比较时间) |
| If-None-Match | 本地资源未修改返回 304(比较标记) |
| User-Agent | 客户端信息 |
| Max-Forwards | 限制可被代理及网关转发的次数 |
| Proxy-Authorization | 向代理服务器发送验证信息 |
| Range | 请求某个内容的一部分 |
| Referer | 表示浏览器所访问的前一个页面 |
| TE | 传输编码方式 |
| 响应字段 | 作用 |
|---|---|
| Accept-Ranges | 是否支持某些种类的范围 |
| Age | 资源在代理缓存中存在的时间 |
| ETag | 资源标识 |
| Location | 客户端重定向到某个 URL |
| Proxy-Authenticate | 向代理服务器发送验证信息 |
| Server | 服务器名字 |
| WWW-Authenticate | 获取资源需要的验证信息 |
| 实体字段 | 作用 |
|---|---|
| Allow | 资源的正确请求方式 |
| Content-Encoding | 内容的编码格式 |
| Content-Language | 内容使用的语言 |
| Content-Length | request body 长度 |
| Content-Location | 返回数据的备用地址 |
| Content-MD5 | Base64加密格式的内容 MD5检验值 |
| Content-Range | 内容的位置范围 |
| Content-Type | 内容的媒体类型 |
| Expires | 内容的过期时间 |
| Last_modified | 内容的最后修改时间 |
# HTTPS
HTTPS 还是通过了 HTTP 来传输信息,但是信息通过 TLS 协议进行了加密。
# TLS
TLS 协议位于传输层之上,应用层之下。首次进行 TLS 协议传输需要两个 RTT ,接下来可以通过 Session Resumption 减少到一个 RTT。
RTT: Round-Trip Time, 往返时延。在计算机⽹络中它是⼀个重要的性能指标,表⽰从发送端发送数据开始,到发送端收到来⾃接收端的确认(接收端收到数据后便立即发送确认),总共经历的时延。
在 TLS 中使用了两种加密技术,分别为:对称加密和非对称加密。
- 对称加密:对称加密就是两边拥有相同的秘钥,两边都知道如何将密文加密解密。
- 非对称加密:有公钥私钥之分,公钥所有人都可以知道,可以将数据用公钥加密,但是将数据解密必须使用私钥解密,私钥只有分发公钥的一方才知道。
TLS 握手过程如下图:
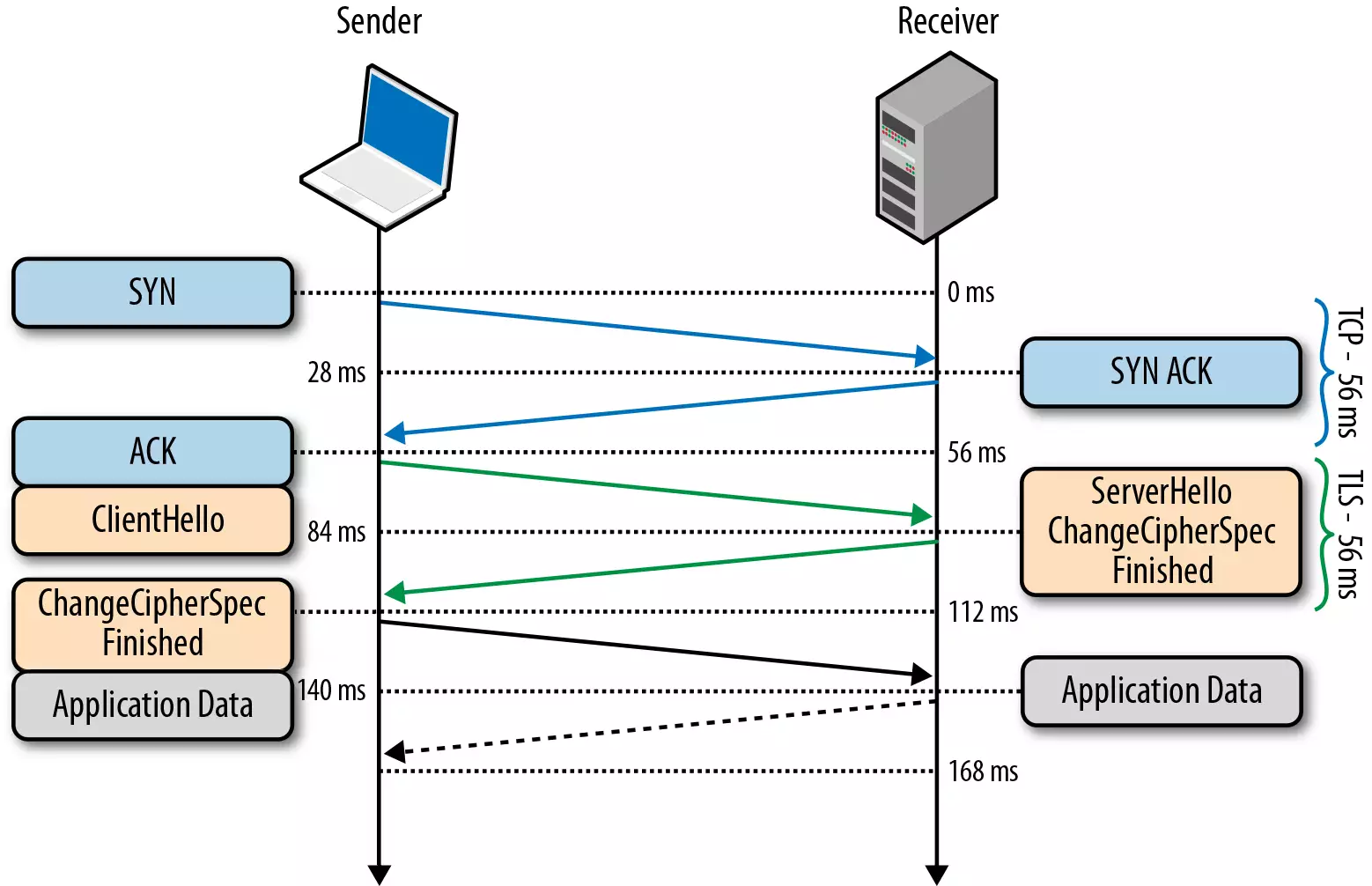
- 客户端发送一个随机值,需要的协议和加密方式
- 服务端收到客户端的随机值,自己也产生一个随机值,并根据客户端需求的协议和加密方式来使用对应的方式,发送自己的证书(如果需要验证客户端证书需要说明)
- 客户端收到服务端的证书并验证是否有效,验证通过会再生成一个随机值,通过服务端证书的公钥去加密这个随机值并发送给服务端,如果服务端需要验证客户端证书的话会附带证书
- 服务端收到加密过的随机值并使用私钥解密获得第三个随机值,这时候两端都拥有了三个随机值,可以通过这三个随机值按照之前约定的加密方式生成密钥,接下来的通信就可以通过该密钥来加密解密
通过以上步骤可知,在 TLS 握手阶段,两端使用非对称加密的方式来通信,但是因为非对称加密损耗的性能比对称加密大,所以在正式传输数据时,两端使用对称加密的方式通信。
PS:以上说明的都是 TLS 1.2 协议的握手情况,在 1.3 协议中,首次建立连接只需要一个 RTT,后面恢复连接不需要 RTT 了。
# HTTP 2.0
HTTP 2.0 相比于 HTTP 1.X,可以说是大幅度提高了 web 的性能。
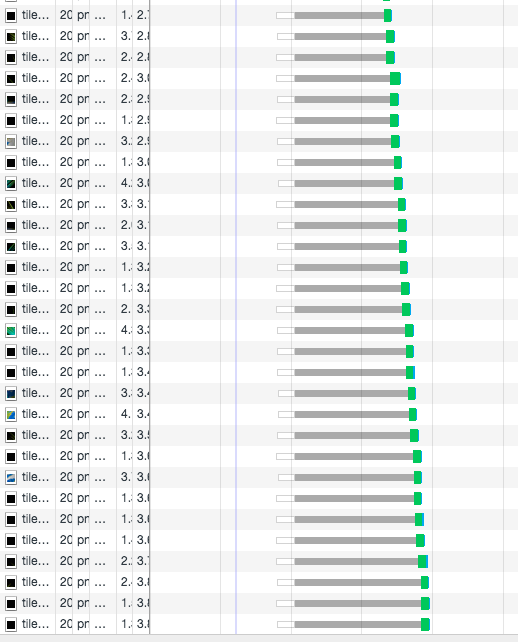
在 HTTP 1.X 中,为了性能考虑,我们会引入雪碧图、将小图内联、使用多个域名等等的方式。这一切都是因为浏览器限制了同一个域名下的请求数量,当页面中需要请求很多资源的时候,队头阻塞(Head of line blocking)会导致在达到最大请求数量时,剩余的资源需要等待其他资源请求完成后才能发起请求。
你可以通过 该链接 (opens new window) 感受下 HTTP 2.0 比 HTTP 1.X 到底快了多少。

在 HTTP 1.X 中,因为队头阻塞的原因,你会发现请求是这样的:
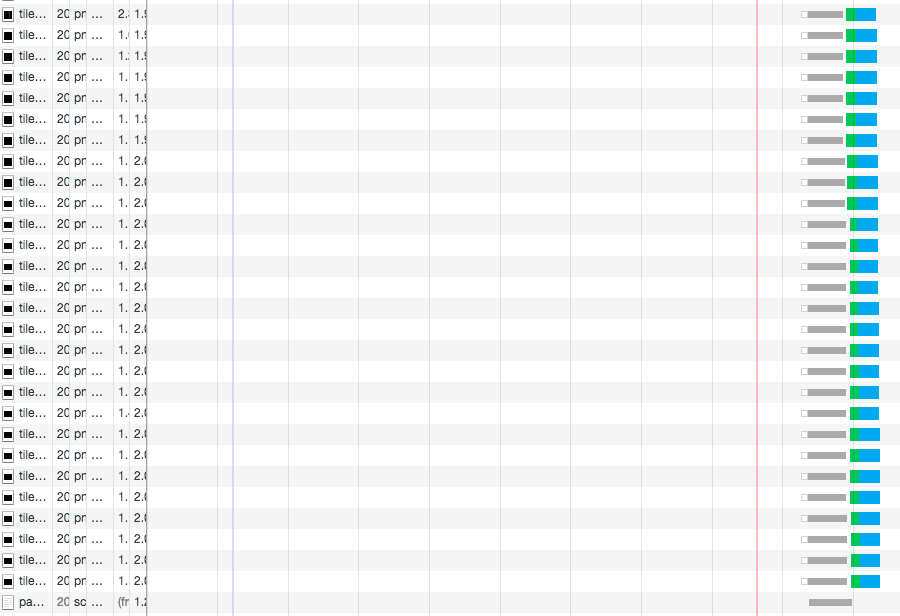
在 HTTP 2.0 中,因为引入了多路复用,你会发现请求是这样的:
# 二进制传输
HTTP 2.0 中所有加强性能的核心点在于此。在之前的 HTTP 版本中,我们是通过文本的方式传输数据。在 HTTP 2.0 中引入了新的编码机制,所有传输的数据都会被分割,并采用二进制格式编码。
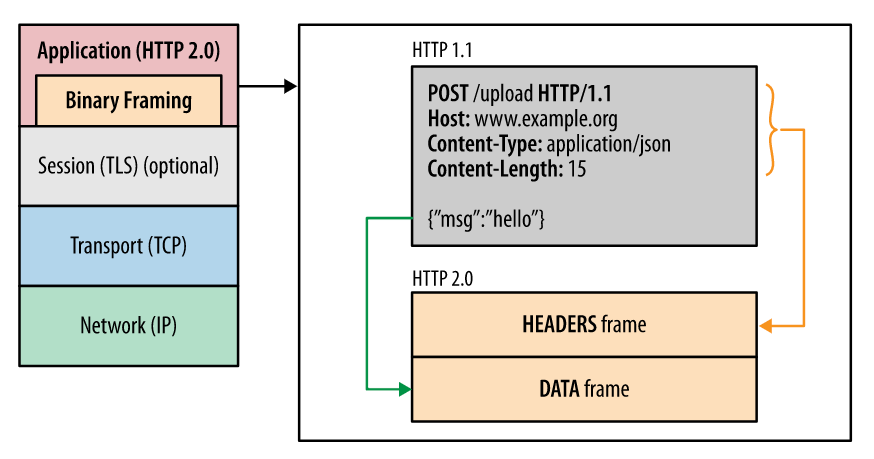
# 多路复用
在 HTTP 2.0 中,有两个非常重要的概念,分别是帧(frame)和流(stream)。
帧代表着最小的数据单位,每个帧会标识出该帧属于哪个流,流也就是多个帧组成的数据流。
多路复用,就是在一个 TCP 连接中可以存在多条流。换句话说,也就是可以发送多个请求,对端可以通过帧中的标识知道属于哪个请求。通过这个技术,可以避免 HTTP 旧版本中的队头阻塞问题,极大的提高传输性能。

# Header 压缩
在 HTTP 1.X 中,我们使用文本的形式传输 header,在 header 携带 cookie 的情况下,可能每次都需要重复传输几百到几千的字节。
在 HTTP 2.0 中,使用了 HPACK 压缩格式对传输的 header 进行编码,减少了 header 的大小。并在两端维护了索引表,用于记录出现过的 header ,后面在传输过程中就可以传输已经记录过的 header 的键名,对端收到数据后就可以通过键名找到对应的值。
# 服务端 Push
在 HTTP 2.0 中,服务端可以在客户端某个请求后,主动推送其他资源。
可以想象以下情况,某些资源客户端是一定会请求的,这时就可以采取服务端 push 的技术,提前给客户端推送必要的资源,这样就可以相对减少一点延迟时间。当然在浏览器兼容的情况下你也可以使用 prefetch 。
# HTTP 3.0
从HTTP/1.0 开始,一直到 HTTP/2,不管应用层协议如何改进,TCP 一直以来都是 HTTP 协议的基础,主要是因为他能提供可靠连接。但是,从HTTP 3.0开始,这个情况就有所变化了。因为,在最新推出的 HTTP 3.0 中,已经彻底弃用 TCP 协议了。
主要原因为:
TCP 对头阻塞 我们知道,TCP 传输过程中会把数据拆分为一个个按照顺序排列的数据包,这些数据包通过网络传输到了接收端,接收端再按照顺序将这些数据包组合成原始数据,这样就完成了数据传输。但是如果其中的某一个数据包没有按照顺序到达,接收端会一直保持连接等待数据包返回,这时候就会阻塞后续请求。这就发生了TCP 队头阻塞。
TCP 握手时长 TCP 的可靠连接是基于三次握手与四次挥手实现的。但是问题是三次握手是需要消耗时间的。TCP 三次握手的过程客户端和服务器之间需要交互三次,那么也就是说需要额外消耗 1.5 RTT。在客户端和服务端距离比较远的情况下,如果一个 RTT 达到300-400ms,那么我握手过程就会显得很「慢」了。
RTT:网络延迟(Round Trip Time)。是指从客户端浏览器发送一个请求数据包到服务器,再从服务器得到响应数据包的这段时间。RTT 是反映网络性能的一个重要指标。
# QUIC
所以,摆在 HTTP/3.0 面前的就只有一条路,那就是放弃 TCP。
于是,HTTP/3.0 在基于 UDP+迪菲赫尔曼算法(Diffie–Hellman)之上实现了 QUIC 协议(Quick UDP Internet Connections)。这是一个谷歌出品的基于 UDP 实现的同为传输层的协议,目标很远大,希望替代 TCP 协议。
QUIC协议有以下特点:
- 基于 UDP 的传输层协议:它使用 UDP 端口号来识别指定机器上的特定服务器
- 可靠性:虽然 UDP 是不可靠传输协议,但是 QUIC 在 UDP 的基础上做了些改造,使得他提供了和 TCP 类似的可靠性。它提供了数据包重传、拥塞控制、调整传输节奏以及其他一些 TCP 中存在的特性。
- 实现了无序、并发字节流:QUIC 的单个数据流可以保证有序交付,但多个数据流之间可能乱序,这意味着单个数据流的传输是按序的,但是多个数据流中接收方收到的顺序可能与发送方的发送顺序不同!
- 快速握手:QUIC 提供 0-RTT 和 1-RTT 的连接建立
- 使用 TLS/1.3 传输层安全协议:与更早的 TLS 版本相比,TLS/1.3 有着很多优点,但使用它的最主要原因是其握手所花费的往返次数更低,从而能降低协议的延迟。
# 参考资料
# HTTP 状态码速查
| 状态代码 | 状态信息 | 含义 |
|---|---|---|
| 100 | Continue | 初始的请求已经接受,客户应当继续发送请求的其余部分。(HTTP 1.1新) |
| 101 | Switching Protocols | 服务器将遵从客户的请求转换到另外一种协议(HTTP 1.1新) |
| 200 | OK | 一切正常,对GET和POST请求的应答文档跟在后面。 |
| 201 | Created | 服务器已经创建了文档,Location头给出了它的URL。 |
| 202 | Accepted | 已经接受请求,但处理尚未完成。 |
| 203 | Non-Authoritative Information | 文档已经正常地返回,但一些应答头可能不正确,因为使用的是文档的拷贝(HTTP 1.1新)。 |
| 204 | No Content | 没有新文档,浏览器应该继续显示原来的文档。如果用户定期地刷新页面,而Servlet可以确定用户文档足够新,这个状态代码是很有用的。 |
| 205 | Reset Content | 没有新的内容,但浏览器应该重置它所显示的内容。用来强制浏览器清除表单输入内容(HTTP 1.1新)。 |
| 206 | Partial Content | 客户发送了一个带有Range头的GET请求,服务器完成了它(HTTP 1.1新)。 |
| 300 | Multiple Choices | 客户请求的文档可以在多个位置找到,这些位置已经在返回的文档内列出。如果服务器要提出优先选择,则应该在Location应答头指明。 |
| 301 | Moved Permanently | 客户请求的文档在其他地方,新的URL在Location头中给出,浏览器应该自动地访问新的URL。 |
| 302 | Found | 类似于301,但新的URL应该被视为临时性的替代,而不是永久性的。注意,在HTTP1.0中对应的状态信息是“Moved Temporatily”。出现该状态代码时,浏览器能够自动访问新的URL,因此它是一个很有用的状态代码。注意这个状态代码有时候可以和301替换使用。例如,如果浏览器错误地请求http://host/~user(缺少了后面的斜杠),有的服务器 返回301,有的则返回302。严格地说,我们只能假定只有当原来的请求是GET时浏览器才会自动重定向。请参见307。 |
| 303 | See Other | 类似于301/302,不同之处在于,如果原来的请求是POST,Location头指定的重定向目标文档应该通过GET提取(HTTP 1.1新)。 |
| 304 | Not Modified | 客户端有缓冲的文档并发出了一个条件性的请求(一般是提供If-Modified-Since头表示客户只想比指定日期更新的文档)。服务器告 诉客户,原来缓冲的文档还可以继续使用。 |
| 305 | Use Proxy | 客户请求的文档应该通过Location头所指明的代理服务器提取(HTTP 1.1新)。 |
| 307 | Temporary Redirect | 和302 (Found)相同。许多浏览器会错误地响应302应答进行重定向,即使原来的请求是POST,即使它实际上只能在POST请求的应答是303时才能重定 向。由于这个原因,HTTP 1.1新增了307,以便更加清除地区分几个状态代码:当出现303应答时,浏览器可以跟随重定向的GET和POST请求;如果是307应答,则浏览器只 能跟随对GET请求的重定向。(HTTP 1.1新) |
| 400 | Bad Request | 请求出现语法错误。 |
| 401 | Unauthorized | 客户试图未经授权访问受密码保护的页面。应答中会包含一个WWW-Authenticate头,浏览器据此显示用户名字/密码对话框,然后在填 写合适的Authorization头后再次发出请求。 |
| 403 | Forbidden | 资源不可用。服务器理解客户的请求,但拒绝处理它。通常由于服务器上文件或目录的权限设置导致。 |
| 404 | Not Found | 无法找到指定位置的资源。这也是一个常用的应答。 |
| 405 | Method Not Allowed | 请求方法(GET、POST、HEAD、DELETE、PUT、TRACE等)对指定的资源不适用。(HTTP 1.1新) |
| 406 | Not Acceptable | 指定的资源已经找到,但它的MIME类型和客户在Accpet头中所指定的不兼容(HTTP 1.1新)。 |
| 407 | Proxy Authentication Required | 类似于401,表示客户必须先经过代理服务器的授权。(HTTP 1.1新) |
| 408 | Request Timeout | 在服务器许可的等待时间内,客户一直没有发出任何请求。客户可以在以后重复同一请求。(HTTP 1.1新) |
| 409 | Conflict | 通常和PUT请求有关。由于请求和资源的当前状态相冲突,因此请求不能成功。(HTTP 1.1新) |
| 410 | Gone | 所请求的文档已经不再可用,而且服务器不知道应该重定向到哪一个地址。它和404的不同在于,返回407表示文档永久地离开了指定的位置,而 404表示由于未知的原因文档不可用。(HTTP 1.1新) |
| 411 | Length Required | 服务器不能处理请求,除非客户发送一个Content-Length头。(HTTP 1.1新) |
| 412 | Precondition Failed | 请求头中指定的一些前提条件失败(HTTP 1.1新)。 |
| 413 | Request Entity Too Large | 目标文档的大小超过服务器当前愿意处理的大小。如果服务器认为自己能够稍后再处理该请求,则应该提供一个Retry-After头(HTTP 1.1新)。 |
| 414 | Request URI Too Long | URI太长(HTTP 1.1新)。 |
| 416 | Requested Range Not Satisfiable | 服务器不能满足客户在请求中指定的Range头。(HTTP 1.1新) |
| 500 | Internal Server Error | 服务器遇到了意料不到的情况,不能完成客户的请求。 |
| 501 | Not Implemented | 服务器不支持实现请求所需要的功能。例如,客户发出了一个服务器不支持的PUT请求。 |
| 502 | Bad Gateway | 服务器作为网关或者代理时,为了完成请求访问下一个服务器,但该服务器返回了非法的应答。 |
| 503 | Service Unavailable | 服务器由于维护或者负载过重未能应答。例如,Servlet可能在数据库连接池已满的情况下返回503。服务器返回503时可以提供一个 Retry-After头。 |
| 504 | Gateway Timeout | 由作为代理或网关的服务器使用,表示不能及时地从远程服务器获得应答。(HTTP 1.1新) |
| 505 | HTTP Version Not Supported | 服务器不支持请求中所指明的HTTP版本。(HTTP 1.1新) |